Recursive Language Models (RLMs): A Brief Overview
Recursive Language Models (RLMs) represent a shift in how AI systems handle massive contexts. Rather than attempting to fit millions of tokens into a single model's window—which often leads to performance degradation known as "Context Rot"—RLMs use a recursive inference strategy to decompose and interact with context programmatically.
The Core Problem: Context Rot
Traditional LLMs suffer from "Context Rot," where accuracy declines as the context window fills, even before reaching technical limits. This isn't just a capacity issue but a quality one; models become "dumber" or lose track of details as the conversation history or input data grows.
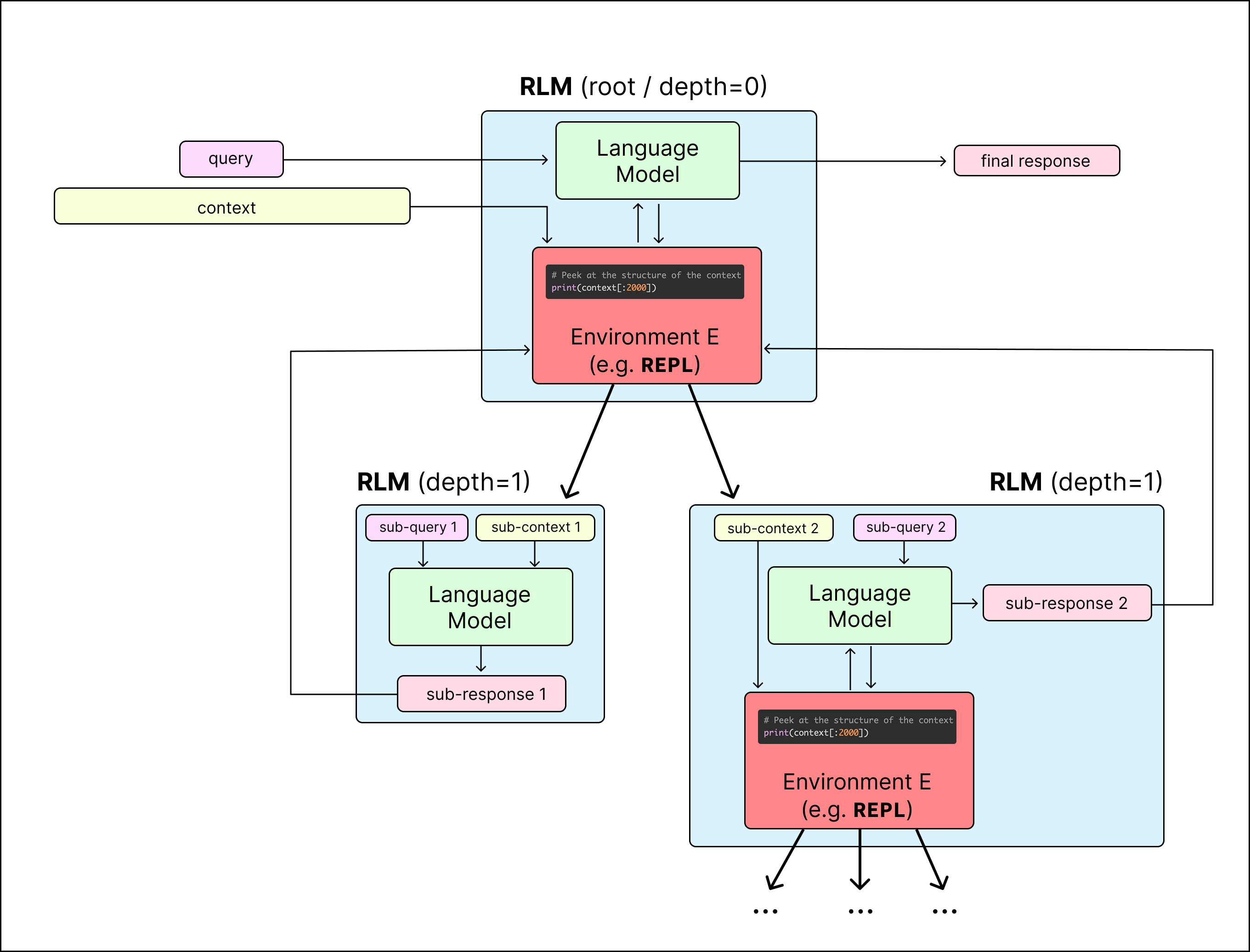
Figure: An RLM interacts with a REPL environment to manage massive context, recursively sub-querying itself or other LMs to efficiently parse information. (Source: alexzhang13.github.io)
How RLMs Work
An RLM is a thin wrapper around a language model that allows it to interact with a computational environment to manage information.
1. Programmatic vs. Tokenized Context
RLMs maintain a distinction between two types of context:
- Programmatic Context: The raw, massive data (e.g., 400MB logs or 10M+ tokens) stored as variables in a coding environment.
- Tokenized Context: The specific snippets of information currently "active" in the LLM's prompt window.
2. The REPL Environment
The RLM operates within a REPL (Read-Eval-Print Loop) environment, typically Python. The long context is loaded as a variable in this environment. The "Root LLM" does not see the entire context; instead, it writes code to explore it.
3. Recursive Decomposition
The Root LLM can call other LLM instances (sub-calls) from within the REPL. This allows for a "divide and conquer" approach:
- Peeking: The model looks at the first few characters to understand the data structure.
- Filtering/Grepping: Using deterministic code (like regex) to narrow down relevant sections.
- Partitioning: Breaking the context into smaller chunks.
- Mapping: Assigning sub-LMs to analyze specific chunks and return summaries.
- Synthesis: The Root LLM gathers all sub-findings to produce a final answer.
Key Benefits
- Unbounded Context: RLMs have demonstrated stable performance on contexts exceeding 10 million tokens, where traditional models fail entirely.
- Deterministic Accuracy: By using code for filtering and searching, RLMs combine the "fuzzy" reasoning of LLMs with the "exact" precision of programmatic tools.
- Efficiency: RLMs can often use smaller, cheaper models (like GPT-4o-mini) for sub-tasks, orchestrated by a stronger "frontier" model, reducing overall costs.
- Inference-Time Scaling: It provides a new axis for scaling performance by allowing the model to "think" longer and perform more iterations during the inference phase.
Getting Started with RLMs
You can easily spin up a new environment and run RLMs in Python.
1. Setup your environment
# Create a new 3.14 environment
uv venv .venv
# Activate it
source .venv/bin/activate
# Install your package (lightning fast)
uv pip install rlms2. Run your first RLM
from rlm import RLM
rlm = RLM(
backend="gemini",
backend_kwargs={"model_name": "gemini-2.0-flash"},
verbose=True, # For printing to console with rich, disabled by default.
)
print(rlm.completion("find the nearest city to stockholm and tell me how far is it in km and the travel time by car to get there.").response)The Future: Agent Discovery
Beyond solving context limits, RLMs act as Agent Discovery Mechanisms. By observing the "traces" of how an RLM solves a complex problem—what strategies it tries, how it chunks data, and which sub-queries it makes—developers can identify repeating patterns. These patterns can then be "hard-coded" into optimized, low-latency agent architectures, effectively using RLMs to "invent" the best agent for a specific task.
Current Limitations
- Latency: Because they often involve multiple synchronous LLM calls, RLMs are currently slower than single-shot completions.
- Model Strength: The Root LLM must be a high-reasoning "frontier" model to effectively manage the REPL and sub-tasking logic.
- Synchronicity: Current implementations are often blocking and do not yet fully utilize asynchronous parallel processing for sub-calls.